9. SELECT 문 응용 - 데이터베이스 구축
저번 시간에는 SQL문의 기본 문법 DDL, DML, DCL(TCL) 등을 학습했습니다. 정보처리기사에서 반드시 나오는 문제들이 므로 이번 파트와 저번 파트는 꼭 공부하셔야합니다.
이번 시간에는 집합연산자, JOIN, 서브쿼리를 배우게 됩니다. 조금만 어렵게 나오면 반드시 나오는 문법들이니 암기하시고 익숙해지시길 바랍니다.
목차
연습할 수 있는 웹사이트
https://www.w3schools.com/sql/
위 사이트는 w3shcool로 sql을 연습할 수 있는 사이트입니다. join은 어려운 것 같은데, 원하시면 mysql과 DBeaver를 활용하시기 바랍니다.
집합 연산자
집합 연산자는 SQL에서 사용되는 도구로, 두 개 이상의 데이터 그룹을 결합하거나 비교하는 데 사용됩니다.
일종의 데이터 "잡합을 만들고 조작하는 도구"로 생각할 수 있습니다.
JOIN과의 차이는 JOIN은 두 테이블 간의 관계를 기반으로 데이터를 결합하는 데 사용됩니다. 예를 들어, 학생 테이블과 과목 테이블이 있다면, JOIN을 사용하여 특정 학생이 수강한 과목을 찾을 수 있습니다.
UNION
여러 테이블 또는 쿼리의 결과를 하나의 리스트로 합칩니다.
중복된 항목은 하나로 합쳐집니다.
예를 들어, A 그룹과 B 그룹의 학생 목록을 합쳐서 중복 학생을 제거하고 전체 학생 목록을 만들 수 있습니다.
SELECT column1, column2 FROM table1
UNION
SELECT column1, column2 FROM table2;


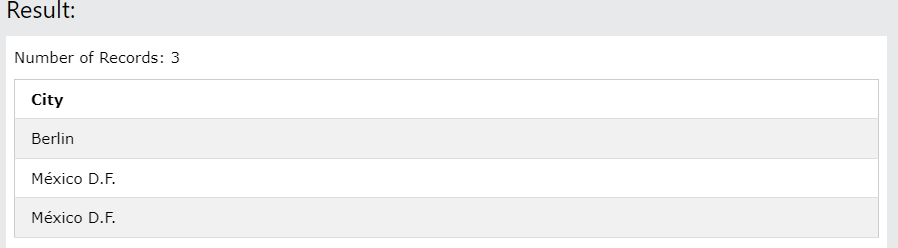
동일한 테이블에서 위에서부터 2개(CustomerID가 1번, 2번) 행과 3개 (CustomerID가 1번, 2번,3번) 의 행을 UNION하면 2번과 3번 행에 있는 México D.F. 이 하나로 합쳐지게 되고 1번의 Berlin이 두번 중복되니, 하나로 나와 최종 2개의 행을 반환하게 됩니다.
UNION ALL
마찬가지로 여러 테이블이나 쿼리의 결과를 합칩니다.
하지만, 중복 항목을 제거하지 않습니다.
따라서 A 그룹과 B 그룹의 학생 목록을 합치면서 중복된 학생을 그대로 유지하게 됩니다.
SELECT column1, column2 FROM table1
UNION ALL
SELECT column1, column2 FROM table2;
| A 그룹 |
| Alice |
| Bob |
| Charlie |
| B 그룹 |
| Alice |
| David |
| Eve |
| 결과 (UNION ALL) |
| Alice(중복) |
| Bob |
| Charlie |
| Alice (중복) |
| David |
| Eve |
INTERSECT
두 데이터 그룹에서 공통된 항목을 찾아냅니다.
예를 들어, A 그룹과 B 그룹의 학생 목록 중에서 두 그룹에 모두 속하는 학생을 찾을 수 있습니다.
중복은 제거 됩니다.
SELECT column1, column2 FROM table1
INTERSECT
SELECT column1, column2 FROM table2;| A 그룹 |
| Alice |
| Bob |
| Charlie |
| B 그룹 |
| Alice |
| David |
| Eve |
| 결과 (INTERSECT): |
| Alice |
EXCEPT(MINUS)
첫 번째 데이터 그룹에서 두 번째 데이터 그룹에 있는 항목을 제거합니다.
예를 들어, A 그룹의 학생 목록에서 B 그룹의 학생 목록을 제거하여 A 그룹에만 속하는 학생을 찾을 수 있습니다
SELECT column1, column2 FROM table1
EXCEPT
SELECT column1, column2 FROM table2;
| A 그룹 |
| Alice |
| Bob |
| Charlie |
| B 그룹 |
| Alice ( A그룹에 Alice만 있으므로 Alice만 삭제) |
| David |
| Eve |
| 결과 (EXCEPT 또는 MINUS): |
| Bob |
| Charlie |
JOIN
정규화의 도부이결다조의 5NF의 join이 현재 설명하는 join입니다.
JOIN은 SQL에서 사용되는 기능 중 하나로, 두 개 이상의 테이블에서 데이터를 결합하는 데 사용됩니다. 일반적으로 JOIN은 두 테이블 사이의 공통된 열(또는 관계)을 기반으로 데이터를 결합합니다.
기본 문법
select와 from까지는 쓰던대로 쓰고 join을 쓴 다음 합칠 테이블명을 적습니다.
그 다음은 어떤 컬럼을 기준으로 합칠지 선택하는 구문을 씁니다. 테이블명.컬럼으로 적으면 됩니다.
Select 컬럼명 FROM 테이블명1
JOIN 테이블명2 ON 테이블1.컬러명 = 테이블2.컬럼명
SELECT column1, column2, ...
FROM table1
JOIN table2 ON table1.column_name = table2.column_name;
SELECT *
FROM 학생
JOIN 수업 ON 학생.학생ID = 수업.학생ID;기본 예시 테이블
두개의 테이블을 합쳐서 보는 것이 join을 쓰는 이유이기 때문에 기본 예시 테이블 두개를 먼저 보여드립니다.
학생 테이블 (Students)
| 학생ID | 이름 | 성별 |
| 1 | Alice | 여성 |
| 2 | Bob | 남성 |
| 3 | Charlie | 남성 |
과목 테이블 (Subjects)
| 학생ID | 과목명 | 성적 |
| 1 | 수학 | A |
| 2 | 영어 | B |
| 3 | 과학 | C |
INNER JOIN
INNER JOIN은 두 테이블 간에 공통된 값을 기준으로 데이터를 결합합니다. 즉, 공통된 값을 가진 행만 결과에 포함됩니다. INNER JOIN은 보통 JOIN이라고도 불립니다.
LEFT OUTER JOIN (또는 LEFT JOIN)LEFT OUTER JOIN은 왼쪽 테이블의 모든 행을 포함하고, 오른쪽 테이블에서 일치하는 행이 있는 경우 해당 행을 결합합니다. 오른쪽 테이블에 일치하는 행이 없는 경우에는 NULL 값이 채워집니다.
SELECT *
FROM Students
INNER JOIN Subjects ON Students.학생ID = Subjects.학생ID;| 학생ID | 이름 | 성별 | 과목명 | 성적 |
| 1 | Alice | 여성 | 수학 | A |
| 2 | Bob | 남성 | 영어 | B |
| 3 | Charlie | 남성 | 과학 | C |
INNER OUTER JOIN (또는 INNER JOIN)
LEFT OUTER JOIN은 왼쪽 테이블의 모든 행을 포함하고, 오른쪽 테이블에서 일치하는 행이 있는 경우 해당 행을 결합합니다. 오른쪽 테이블에 일치하는 행이 없는 경우에는 NULL 값이 채워집니다
SELECT *
FROM Students
LEFT JOIN Subjects ON Students.학생ID = Subjects.학생ID;| 학생ID | 이름 | 성별 | 과목명 | 성적 |
| 1 | Alice | 여성 | 수학 | A |
| 2 | Bob | 남성 | 영어 | B |
| 3 | Charlie | 남성 | 과학 | C |
| NULL | NULL | NULL | NULL | NULL |
RIGHT OUTER JOIN (또는 RIGHT JOIN)
오른쪽 테이블의 모든 행을 포함하고, 왼쪽 테이블에서 일치하는 행이 있는 경우 해당 행을 결합합니다. 왼쪽 테이블에 일치하는 행이 없는 경우에는 NULL 값이 채워집니다.
SELECT *
FROM Students
LEFT JOIN Subjects ON Students.학생ID = Subjects.학생ID;FULL OUTER JOIN (또는 FULL JOIN)
FULL OUTER JOIN은 두 테이블 중 어느 한 쪽에도 일치하지 않는 행을 포함하여 결과를 반환합니다. 즉, 양쪽 테이블의 모든 행을 포함합니다. 어느 한 쪽에만 해당하는 행은 다른 쪽의 값이 NULL로 표시됩니다.
SELECT *
FROM Students
FULL JOIN Subjects ON Students.학생ID = Subjects.학생ID;
| 학생ID | 이름 | 성별 | 과목명 | 성적 |
| 1 | Alice | 여성 | 수학 | A |
| 2 | Bob | 남성 | 영어 | B |
| 3 | Charlie | 남성 | 과학 | C |
| NULL | NULL | NULL | NULL | NULL |
CROSS JOIN
CROSS JOIN은 첫 번째 테이블의 각 행과 두 번째 테이블의 모든 행을 결합합니다. 따라서 CROSS JOIN은 두 테이블의 모든 가능한 조합을 반환합니다. 결과 행 수는 첫 번째 테이블의 행 수와 두 번째 테이블의 행 수의 곱과 동일합니다.
SELECT *
FROM Students
CROSS JOIN Subjects;학생ID이름성별과목명성적
| 1 | Alice | 여성 | 수학 | A |
| 1 | Alice | 여성 | 영어 | B |
| 1 | Alice | 여성 | 과학 | C |
| 2 | Bob | 남성 | 수학 | A |
| 2 | Bob | 남성 | 영어 | B |
| 2 | Bob | 남성 | 과학 | C |
| 3 | Charlie | 남성 | 수학 | A |
| 3 | Charlie | 남성 | 영어 | B |
| 3 | Charlie | 남성 | 과학 | C |
자연 조인(Natural Join)
두 테이블 간의 공통된 열의 값이 일치하는 행만 결합하는 JOIN 종류 중 하나입니다.
Natural Join은 ON 절을 사용하여 특정 조인 조건을 명시적으로 지정하지 않고, 두 테이블의 공통된 열을 기준으로 자동으로 조인합니다.
SELECT *
FROM Students
NATURAL JOIN Subjects;
| 학생ID | 이름 | 성별 | 과목명 | 성적 |
| 1 | Alice | 여성 | 수학 | A |
| 2 | Bob | 남성 | 영어 | B |
| 3 | Charlie | 남성 | 과학 | C |
서브쿼리
서브쿼리(Subquery)는 하나의 SQL 문 안에서 또 다른 SQL 문을 포함하는 것을 말합니다.
쉽게 말해, SQL 문 안에 있는 또 다른 SQL 문이라고 생각하면 됩니다. 서브쿼리는 주로 WHERE 절, FROM 절, SELECT 절 안에서 사용됩니다.
WHERE 절에서의 서브쿼리
WHERE 절에서 서브쿼리를 사용하여 특정 조건을 만족하는 데이터를 필터링할 수 있습니다. 아래 예시는 과목이 '수학'인 학생들을 선택합니다.
SELECT *
FROM Students
WHERE 학생ID IN (SELECT 학생ID FROM Subjects WHERE 과목명 = '수학');| 학생ID | 이름 | 성적 |
| 1 | Alice | 85 |
| 3 | Charlie | 75 |
FROM 절에서의 서브쿼리
FROM 절에서 서브쿼리를 사용하여 다른 테이블로부터 데이터를 가져올 수 있습니다. 아래 예시는 과목이 '수학'인 학생들의 성적을 평균내어 출력합니다
from 절의 select 문부터 처리를 해줘야합니다.
SELECT AVG(성적) AS 수학평균성적
FROM (SELECT 성적 FROM Students WHERE 학생ID IN (SELECT 학생ID FROM Subjects WHERE 과목명 = '수학')) AS MathScores;| 수학평균성적 |
| 80 |
SELECT 절에서의 서브쿼리
SELECT 절에서 서브쿼리를 사용하여 추가적인 데이터를 조회할 수 있습니다. 아래 예시는 각 학생의 성적과 함께 해당 학생의 과목을 출력합니다.
SELECT 학생ID, 이름, 성적, (SELECT 과목명 FROM Subjects WHERE Subjects.학생ID = Students.학생ID) AS 과목
FROM Students;| 학생ID | 이름 | 성적 | 과목 |
| 1 | Alice | 85 | 수학 |
| 2 | Bob | 90 | 영어 |
| 3 | Charlie | 75 | 수학 |
| 4 | David | 80 | 과학 |
서브쿼리 종류
스칼라 서브쿼리
스칼라 서브쿼리는 서브쿼리의 결과가 단일한 스칼라 값(한 개의 행, 한 개의 열)을 반환하는 서브쿼리입니다. 이러한 서브쿼리는 주로 SELECT 절이나 WHERE 절에서 사용됩니다. 주로 단일행 서브쿼리라고도 불립니다.
예를 들어, 아래의 쿼리는 스칼라 서브쿼리를 사용하여 과목 '수학'의 평균 성적을 조회합니다.
SELECT
(SELECT AVG(성적) FROM 학생 WHERE 과목 = '수학') AS 수학평균성적;인라인뷰 서브쿼리
인라인뷰 서브쿼리는 서브쿼리의 결과를 임시 테이블로 취급하여 FROM 절에서 사용하는 것입니다. 이렇게 사용된 서브쿼리는 외부 쿼리에서는 하나의 테이블로 취급됩니다.
예를 들어, 아래의 쿼리는 인라인뷰 서브쿼리를 사용하여 '수학' 과목의 학생들만을 조회합니다.
SELECT *
FROM (SELECT * FROM 학생 WHERE 과목 = '수학') AS MathStudents;
중첩 서브쿼리
중첩 서브쿼리는 하나의 쿼리 안에 또 다른 쿼리가 포함된 형태입니다. 이러한 서브쿼리는 주로 WHERE 절이나 HAVING 절에서 사용됩니다. 중첩 서브쿼리는 단일 행 또는 다중 행을 반환할 수 있습니다.
단일행 중첩 서브쿼리 (Single-Row Nested Subquery)
단일행 중첩 서브쿼리는 서브쿼리의 결과가 한 개의 행을 반환하는 것입니다. 이러한 서브쿼리는 주로 비교 연산자와 함께 사용됩니다.
예를 들어, 아래의 쿼리는 단일행 중첩 서브쿼리를 사용하여 성적이 평균 이상인 학생을 조회합니다.
SELECT *
FROM 학생
WHERE 성적 > (SELECT AVG(성적) FROM 학생);다중행 중첩 서브쿼리 (Multiple-Row Nested Subquery)
다중행 중첩 서브쿼리는 서브쿼리의 결과가 여러 개의 행을 반환하는 것입니다. 이러한 서브쿼리는 주로 IN, ANY, ALL 등의 비교 연산자와 함께 사용됩니다.
| 서브쿼리 | 형태비교 | 연산자설명 |
| IN 서브쿼리 | IN | 서브쿼리의 결과가 비교 대상 값들 중 하나와 일치하는지를 판별합니다. |
| EXISTS 서브쿼리 | EXISTS | 서브쿼리의 결과가 적어도 한 개 이상의 행을 반환하는지 여부를 판별합니다. |
| ANY 서브쿼리 | =, >, < 등 | 서브쿼리의 결과 중 하나라도 비교 연산자와 만족하는지를 판별합니다. 서브쿼리 조건이 둘중 하나라도 만족해야한다. |
| ALL 서브쿼리 | =, >, < 등 | 서브쿼리의 결과가 비교 대상 값들 중 모든 값과 비교 연산자를 만족하는지를 판별합니다. 서브쿼리가 모두 만족해야한다. |
예시 테이블
| 학생ID | 이름 | 성적 |
| 1 | Alice | 85 |
| 2 | Bob | 90 |
| 3 | Charlie | 75 |
| 4 | David | 80 |
IN 연산자를 사용한 예시
- IN 서브쿼리는 서브쿼리의 결과가 메인 쿼리의 조건과 일치하는 값을 반환합니다.
- 아래의 쿼리는 "성적이 90 이상인 학생들"을 선택하는 것으로, 서브쿼리에서는 성적이 90 이상인 학생들의 학생ID를 반환하고, 메인 쿼리에서는 이 학생ID에 해당하는 학생들을 선택합니다.
SELECT *
FROM 학생
WHERE 학생ID IN (SELECT 학생ID FROM 성적 WHERE 성적 > 90);| 학생ID | 이름 | 성적 |
| 2 | Bob | 90 |
EXISTS 연산자를 사용한 예시
- EXISTS 서브쿼리는 서브쿼리의 결과가 적어도 한 개 이상의 행을 반환할 때 참이 됩니다.
- 이래 쿼리는 "성적 테이블에 해당 학생ID가 있는지 여부"를 확인하는 것으로, 서브쿼리에서는 성적 테이블에서 학생ID를 찾고, 메인 쿼리에서는 이 결과에 따라 해당하는 학생들을 선택합니다.
SELECT *
FROM 학생 AS S
WHERE EXISTS (SELECT * FROM 성적 AS G WHERE G.학생ID = S.학생ID AND G.성적 > 90);| 학생ID | 이름 | 성적 |
| 1 | Alice | 85 |
| 2 | Bob | 90 |
| 3 | Charlie | 75 |
| 4 | David | 80 |
ANY 연산자를 사용한 예시
- ANY 서브쿼리는 서브쿼리의 결과 중 하나라도 비교 연산자와 만족하면 참이 됩니다.
- 아래 쿼리는 "학생의 성적이 해당 학생의 성적 중 적어도 하나와 같거나 높은지"를 확인하는 것으로, 서브쿼리에서는 해당 학생ID의 성적들을 반환하고, 메인 쿼리에서는 이 결과와 비교하여 해당하는 학생들을 선택합니다.
SELECT *
FROM 학생 AS S
WHERE 성적 > ANY (SELECT 성적 FROM 성적 AS G WHERE G.학생ID = S.학생ID);| 학생ID | 이름 | 성적 |
| 1 | Alice | 85 |
| 2 | Bob | 90 |
| 3 | Charlie | 75 |
| 4 | David | 80 |
ALL 연산자를 사용한 예시
- ALL 서브쿼리는 서브쿼리의 결과가 비교 대상 값들 중 모든 값과 비교 연산자를 만족할 때 참이 되는 조건을 설정할 때 사용
- 위의 예시에서는 "학생의 성적이 해당 학생의 성적 중 모든 값보다 크거나 같은 경우"를 조건으로 설정하였습니다. 이 경우, 메인 쿼리의 각 학생에 대해 해당 학생의 성적이 모든 다른 학생들의 성적보다 크거나 같은지를 확인합니다.
SELECT *
FROM 학생 AS S
WHERE 성적 > ALL (SELECT 성적 FROM 성적 AS G WHERE G.학생ID = S.학생ID);| 학생ID | 이름 | 성적 |
| 1 | Alice | 85 |
| 2 | Bob | 90 |
| 3 | Charlie | 75 |
| 4 | David | 80 |
'정보처리기사' 카테고리의 다른 글
| 11. 병행제어와 데이터 전환 - 2과목 데이터 베이스 구축 (0) | 2024.04.05 |
|---|---|
| 10. SQL 그룹함수, 절차형 SQL - 2과목 데이터베이스 구축 (1) | 2024.04.04 |
| 8. SQL의 기본기 - 데이터베이스구축 (0) | 2024.04.02 |
| 7. 물리데이터모델 품질 검토 & 분산 데이터 베이스 - 2과목 데이터 베이스 구축 (0) | 2024.04.02 |
| 6. 키와 무결성 제약조건 - 2과목 데이터 베이스 구축 - 릴레이션, 속성, 키 (0) | 2024.04.01 |




댓글