[정처기] 비개발자 파이썬 기본 문제 잡기

파이썬은 C언어와 JAVA처럼 복잡한 내용은 적지만 암기 내용이 많습니다. 암기만 잘하면 모두 맞출 수 있는 문제이기 때문에 포기하지 마시고 꼭 확인하고 시험에 임하셨으면 좋겠습니다.
슬라이싱해서 출력하는 문이 []를 포함한 자료형태를 가져오게 되고 그냥 값을 지목하는 경우에는 값 자체만 출력할 수도 있습니다. 함수에서 쓰이는 sel이 this를 뜻하는 것과 lambda 함수가 값을 가져와 연산하는 것 등 다양한 것들이 있지만 다른 언어에 비해 몇 번보면 간단합니다. JAVA처럼 상속, 생성자보면서 어떻게 흘러가야하는지 흐름을 본다거나 C언어 처럼 배열과 포인터로 헷갈리는 일이 적으니 꼭 확인하여 1~2문제를 맞춰보세요
목차
파이썬 기본 필수 암기 내용
1. 논리연산자에 대한 출력
파이썬에서는 논리 연산자의 결과로 False와 True가 나타납니다. 이는 조건식의 결과가 참이냐 거짓이냐에 따라 출력되는 값입니다. 예를 들어, 1 == 2와 같이 서로 같지 않은 두 값을 비교하면 False가 출력됩니다.
print(1 == 2) # 1은 2와 같지 않으므로 False가 출력됩니다.대문자로 시작한다는 점 꼭 기억하세요!
실제 정처기 실기 시험에 출제된 적이 있는 문제입니다.
2. 연산의 특이사항
// 파이썬에서는 /만 쓰면 실수가 나올 수 있습니다.
정수로 출력하려면 //을 써야합니다.
- print(5 / 2) # 결과: 2.5
print(5 // 2) # 결과: 2
%의 경우에는 어떨까요?
%는 무관하게 정수로 출력됩니다. 별도의 실수형 double이나 float이 아니면 정수로 나옵니다.
예를 들어, 5 / 2를 연산하면 2.5가 출력되며, 5 // 2를 연산하면 2가 출력됩니다.
print(5 / 2) # 5를 2로 나누면 2.5가 출력됩니다.
print(5 // 2) # 정수로 나누면 2가 출력됩니다.
print(5 % 2) # 나머지 연산을 하면 1이 출력됩니다.
*늘 헷갈릴 수 있는 연산 1/7 = 0, 1%7=1
꼭 기억하세요, 분모가 분자보다 큰 경우 정수에서는 나누기가 불가능합니다.
그러므로 몫은 늘 0이며, 나머지는 분자가 됩니다.
3. 특성을 바꾸는 함수
파이썬에서는 str() 함수를 사용하여 값을 문자열로 변환할 수 있습니다.
다른 자료형을 바꾸는 함수로는 int(), float(), list() 등이 있습니다. 예를 들어, str(123)을 호출하면 정수 123이 문자열로 변환되어 "123"이 출력됩니다. .
print(str(123)) # 정수 123을 문자열 "123"로 변환하여 출력합니다.
print(int("123")) # 문자열 "123"을 정수 123으로 변환하여 출력합니다.
num = 123
print(str(num)) # 결과: "123"
string = "456"
print(int(string)) # 결과: 456
4. 반복문 특징
while문
while 문과 같은 반복문에서 continue는 다시 반복문을 돌게 됩니다.
while 문에서 True를 사용하여 무한 반복을 수행할 수 있습니다. 이때, 반복을 멈추기 위해서는 특정 조건을 만족할 때 break문을 사용합니다. 예를 들어, while True:로 시작하는 루프는 계속해서 반복됩니다.
whie(True) : // continue에서 다시 돌아와 AB만 무한 출력
print('A')
print('B')
continue
print('C')for 문
for i in range(5):
print(i)
#결과
#0
#1
#2
#3
#4
5. if 문 특징
조건문에서는 elif를 사용하여 여러 조건을 처리할 수 있습니다. 이는 여러 조건을 순차적으로 검사하고, 해당하는 조건을 만족할 때 실행됩니다. 예를 들어, 어떤 수가 음수인지, 0인지, 양수인지를 판단하는 조건문에서는 elif를 사용할 수 있습니다.
x = 10
if x < 0:
print("음수")
elif x == 0:
print("0")
else:
print("양수")
6. 파이썬 출력문 특징
[1,2,3] 그리고 "a"와 같이 출력되는 경우가 있고
다른 언어와 같이 1,2,3 그리고 a와 같이 값이 나오는 경우가 있습니다.
파이썬에서는 리스트나 문자열을 그대로 출력할 수 있습니다.
이는 print() 함수를 사용하여 변수나 값을 출력할 때 적용됩니다. 리스트는 대괄호로, 문자열은 따옴표로 감싸여서 출력됩니다.
# 직접 출력하는 경우는 그대로 출력
print([1, 2, 3]) # 리스트 [1, 2, 3]를 출력합니다.
print("a") # 문자열 "a"를 출력합니다.
my_list = [1, 2, 3]
print(my_list) # 결과: [1, 2, 3]
my_string = "Hello"
print(my_string) # 결과: "Hello"
7. 클래스 선언 및 사용 방법
파이썬은 객체지향언어이며 클래스를 사용하여 객체를 정의할 수 있습니다.
클래스는 변수와 메서드를 포함하며, 객체를 생성할 때 사용됩니다. 이때, 클래스의 인스턴스를 만들고 이를 사용하여 데이터와 함수를 조직화합니다.
자바와의 차이는 들여쓰기가 기본 적입니다. {} 중괄호를 쓰지 않으니 주의하세요
class Dog:
def __init__(self, name):
self.name = name
def bark(self):
print(f"{self.name}가 짖습니다.")
my_dog = Dog("멍멍이")
my_dog.bark() # 결과: "멍멍이가 짖습니다."
클래스는 함수(메서드)를 구현하기 위해 많이 쓰는데, 자바의 this가 파이썬의 sel(self)임을 기억하셔야합니다.
class MyClass:
def method(self, a, b):
print(self, a, b)
obj = MyClass()
obj.method(1, 2) # 출력: <__main__.MyClass object at 0x7f5c2843b550> 1 2위의 형식은 일반적으로 파이썬 클래스에서 메서드를 정의할 때 사용됩니다.
self는 현재 인스턴스를 가리키는 것으로, 클래스의 인스턴스를 생성할 때 자동으로 전달됩니다.
따라서 이런 형태의 메서드를 호출할 때는 인스턴스를 호출해야 합니다.
8.슬라이싱
슬라이싱은 리스트나 문자열과 같은 시퀀스 자료형에서 일부를 추출하는 방법입니다. 시작, 끝, 단계(step)을 지정하여 원하는 부분을 가져올 수 있습니다.
[시작:끝:단계]
가장 중요한 것은 끝 숫자 앞까지 입니다. "끝(나)을 제외하고"라고 되뇌이며 문제를 푸셔야합니다.
슬라이싱은 콜론(:)을 사용하여 시작과 끝 인덱스를 지정하며, 단계는 옵션입니다.
슬라이싱에 시작 부분이 비어있으면 0부터 가져오는데요, 이는 파이썬에서의 슬라이싱 특성 중 하나입니다.
시작 부분이 생략되면 기본적으로 0으로 간주되어 리스트나 문자열의 시작부터 해당 인덱스까지의 요소를 가져옵니다
a=[10,20,30,40,50,60,70,80,90,100,110,120]
a[0:8:2]
a = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120]
print(a[0:8:2]) # 리스트 a에서 0부터 8까지 2씩 증가하면서 가져옵니다.
my_set = {1, 2, 3}
print(my_set) # 세트 {1, 2, 3}를 출력합니다.
my_list = [1, 2, 3, 4, 5]
print(my_list[1:4]) # 결과: [2, 3, 4]{세트}는 키를 검색하면 값이 나옵니다.
my_set = {1, 2, 3, 4, 5}
print(3 in my_set) # 결과: True
슬라이싱이 어디서 끝나는지 꼭 확인해야합니다.
자료형에 따른 특징은 기존 글을 확인해부세요
[정처기] 비개발자 파이썬 기초 - 6과목 프로그래밍 언어
[비개발자용] 파이썬 기초 - 6과목 프로그래밍 언어 지난 시간은 JAVA에 대한 기초를 공부했습니다. C와 JAVA는 한 시험에 2~3개씩 출제되기 때문에 필수로 확인해야합니다. 생성자, 오버로딩, 오버
shareknowledge-top.tistory.com
s = "abcdef"
print(s[:3]) # 문자열 "abcdef"에서 처음부터 3번째 인덱스까지 가져옵니다.
{}안에도 key:value 형태가 가능합니다.
del my_dict['banana']가 가능합니다.
my_dict['pear']=4도 가능합니다.
왜 그러냐면 이 자료형이 dictionary 형태이기 때문입니다.
9. 파이썬 리스트에서 쓰이는 함수
| 함수 | 설명 |
| append() | 리스트의 끝에 요소를 추가합니다. |
| clear() | 리스트의 모든 요소를 제거합니다. |
| copy() | 리스트의 복사본을 반환합니다. |
| count() | 리스트에서 특정 요소의 개수를 세어 반환합니다. |
| extend() | 리스트에 다른 리스트나 반복 가능한 객체의 모든 요소를 추가합니다. |
| index() | 리스트에서 특정 요소의 인덱스를 반환합니다. |
| insert() | 지정된 위치에 요소를 삽입합니다. |
| pop() | 리스트에서 마지막 요소를 제거하고 반환합니다. |
| remove() | 리스트에서 특정 값을 가진 첫 번째 요소를 제거합니다. |
| reverse() | 리스트의 요소 순서를 반대로 뒤집습니다. |
| sort() | 리스트를 정렬합니다. 기본적으로 오름차순으로 정렬하며, reverse=True 옵션을 사용하여 내림차순으로 정렬할 수 있습니다. |
10. 특별한 함수
Split() 리스트형태로 변화하는 예시
lamda 사용법
람다(lambda)는 파이썬에서 간단한 익명 함수를 만들 때 사용됩니다. 일반적인 함수와는 달리 함수 이름이 없으며, 한 줄로 표현될 수 있는 간단한 함수를 정의할 때 주로 사용됩니다.
lambda 인자: 표현식
add = lambda x, y: x + y
print(add(3, 5)) # 결과: 8# 주어진 리스트
numbers = [1, 2, 3, 4, 5]
# 리스트 컴프리헨션을 사용하여 홀수만 필터링하고 그 합계를 계산합니다.
total = sum([n for n in numbers if n % 2 == 1])- numbers = [1, 2, 3, 4, 5]: 주어진 리스트입니다. 이 리스트에는 다양한 정수가 포함되어 있습니다.
- 리스트 컴프리헨션을 사용하여 홀수만 필터링하고 그 합계를 계산합니다.
- [n for n in numbers if n % 2 == 1]: 리스트 컴프리헨션을 사용하여 주어진 리스트 numbers의 각 요소 n에 대해 조건식 n % 2 == 1을 만족하는 홀수만을 선택합니다. % 연산자는 주어진 숫자를 2로 나눈 나머지를 반환하므로, 홀수는 나머지가 1인 경우입니다. 이렇게 선택된 홀수들은 새로운 리스트에 포함됩니다.
- sum(): 리스트의 합계를 계산하는 파이썬 내장 함수입니다. 선택된 홀수들의 리스트를 sum() 함수에 전달하여 그 합계를 계산합니다.
- total: 홀수들의 합계를 저장하는 변수입니다. 이 변수에는 선택된 홀수들의 총합이 저장됩니다.
1. map() 함수와 함께 사용하기
map() 함수는 반복 가능한(iterable) 객체의 각 요소에 함수를 적용하여 새로운 이터레이터(iterator)를 생성합니다. 람다 함수를 map() 함수와 함께 사용하면 편리합니다.
numbers = [1, 2, 3, 4, 5]
squared = map(lambda x: x ** 2, numbers)
print(list(squared)) # 결과: [1, 4, 9, 16, 25]2. filter() 함수와 함께 사용하기
filter() 함수는 반복 가능한(iterable) 객체의 요소 중에서 주어진 함수의 조건을 만족하는 요소만을 필터링하여 새로운 이터레이터(iterator)를 생성합니다. 람다 함수를 filter() 함수와 함께 사용하면 특정 조건을 만족하는 요소를 필터링할 수 있습니다.
numbers = [1, 2, 3, 4, 5]
odd_numbers = filter(lambda x: x % 2 == 1, numbers)
print(list(odd_numbers)) # 결과: [1, 3, 5]위 코드에서는 주어진 리스트 numbers에서 홀수만을 필터링하는 람다 함수를 filter() 함수와 함께 사용하여 새로운 리스트를 생성합니다.
3. 정렬 기준으로 사용하기
sorted() 함수는 정렬할 때 특정 기준을 사용할 수 있는데, 이때 람다 함수를 정렬 기준으로 사용할 수 있습니다.
students = [
{'name': 'Alice', 'score': 80},
{'name': 'Bob', 'score': 90},
{'name': 'Charlie', 'score': 70}
]
sorted_students = sorted(students, key=lambda x: x['score'])
print(sorted_students)
4. max와 함께 쓰기
max() 함수는 반복 가능한(iterable) 객체에서 최대값을 반환하는 함수입니다. 람다 함수를 max() 함수와 함께 사용하여 특정 기준에 따라 최대값을 찾을 수 있습니다.
예를 들어, 리스트 안에 있는 숫자 중에서 절댓값이 가장 큰 숫자를 찾는 예시를 살펴보겠습니다.
numbers = [-3, 5, -9, 7, -2]
max_abs = max(numbers, key=lambda x: abs(x))
print(max_abs) # 결과: -9위 코드에서는 max() 함수를 사용하여 numbers 리스트에서 절댓값이 가장 큰 숫자를 찾습니다. key 매개변수에 람다 함수를 사용하여 절댓값을 기준으로 최대값을 찾게 됩니다.
따라서 max() 함수는 절댓값이 가장 큰 숫자인 -9를 반환합니다.
max함수가 정처기 문제로 나올때 문자열(str)로 나올 수 있습니다. 이때는 문자의 크기(아스키코드)로 확인해야합니다.
text = "hello world"
max_char = max(text, key=lambda x: ord(x))
print(max_char) # 결과: 'w'위 코드에서는 max() 함수를 사용하여 문자열 text에서 아스키코드 기준으로 가장 큰 문자를 찾습니다. 람다 함수를 사용하여 각 문자를 ord() 함수를 이용하여 아스키코드로 변환한 후, 이를 기준으로 최대값을 찾습니다. 따라서 max() 함수는 아스키코드 기준으로 가장 큰 문자인 'w'를 반환합니다.
sort() 함수
자동으로 정렬을 해주는 함수입니다. 파이썬에서는 정렬을 위한 알고리즘을 구현할 필요가 없이 편리하게 구현가능 합니다.
sort() 함수는 리스트의 요소를 정렬합니다. 기본적으로는 오름차순(작은 값부터 큰 값 순서)으로 정렬되며, reverse=True 옵션을 추가하여 내림차순(큰 값부터 작은 값 순서)으로 정렬할 수도 있습니다. 원본 리스트를 직접 변경하며, 새로운 리스트를 반환하지 않습니다.
numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
numbers.sort()
print(numbers) # 출력: [1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 9]
numbers.sort(reverse=True)
print(numbers) # 출력: [9, 6, 5, 5, 5, 4, 3, 3, 2, 1, 1]11 . 집합 함수
1. intersection() 함수
intersection() 함수는 두 개의 집합 사이의 공통된 요소들로 이루어진 새로운 집합을 반환합니다.
1. intersection() 함수
intersection() 함수는 두 개의 집합 사이의 공통된 요소들로 이루어진 새로운 집합을 반환합니다.2. union() 함수
union() 함수는 두 개의 집합을 합쳐서 하나의 집합으로 만듭니다. 중복된 요소는 하나로 취급됩니다
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
union_set = set1.union(set2)
print(union_set) # 출력: {1, 2, 3, 4, 5, 6, 7, 8}3. difference() 함수
difference() 함수는 첫 번째 집합에서 두 번째 집합에 포함되지 않는 요소들로 이루어진 새로운 집합을 반환합니다.
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
difference_set = set1.difference(set2)
print(difference_set) # 출력: {1, 2, 3}
필수 기초 사항 - 전역변수, 지역변수, 정적변수
1. 전역 변수(Global Variable)
전역 변수는 프로그램 전체에서 사용할 수 있는 변수입니다. 프로그램이 실행되는 동안에는 어디서든 접근할 수 있습니다. 보통 함수 밖에서 정의되며, 함수 내에서도 접근 가능합니다.
2. 지역 변수(Local Variable)
지역 변수는 특정한 범위(예: 함수 내부)에서만 사용할 수 있는 변수입니다. 함수가 호출될 때 생성되고, 함수가 종료되면 소멸됩니다. 다른 함수나 코드 블록에서는 접근할 수 없습니다.
3. 정적 변수(Static Variable)
정적 변수는 클래스의 모든 인스턴스에서 공유되는 변수입니다. 클래스 내부에서 정의되며, 모든 인스턴스가 이 변수를 공유하게 됩니다.
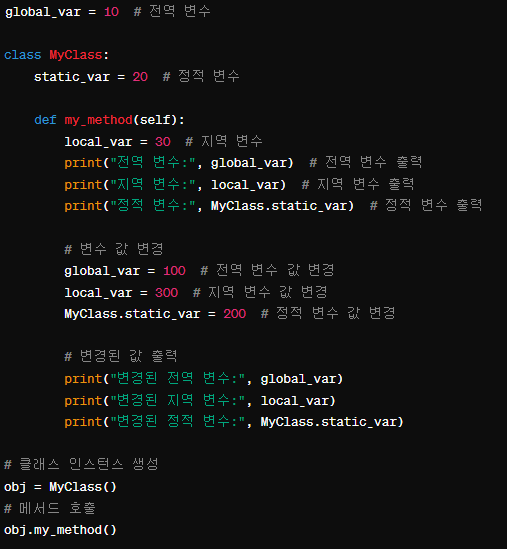
- 전역 변수: 10
- 지역 변수: 30
- 정적 변수: 20
- 변경된 전역 변수: 100
- 변경된 지역 변수: 300
- 변경된 정적 변수: 200
'정보처리기사' 카테고리의 다른 글
| 인터페이스 검증 도구 STAF와 Selennium 차이 (0) | 2024.04.20 |
|---|---|
| [정처기 실기] 암호화 알고리즘 예상문제 (3) | 2024.04.20 |
| [정처기] 비개발자 파이썬 기초 - 6과목 프로그래밍 언어 (0) | 2024.04.14 |
| [정처기] 비개발자 JAVA 기초 - 6과목 프로그래밍 언어 (0) | 2024.04.13 |
| [정처기] 비개발자 C언어 기초 - 6과목 프로그래밍 언어 (1) | 2024.04.13 |


댓글