
파이썬으로 데이터를 기본적으로 다룰 줄 알아야 시험 문제를 제출할 수 있습니다.
데이터를 불러오고 가공하는 것이 가장 중요한 파트일 수 있으니, 자주 살펴봐야할 것 같습니다. 시간이 많이 없을 직장인 분들은 반복적으로 확인해보시길 바랍니다.
데이터 불러오기
local이건 cloud건 데이터를 불러와야 분석을 할 수 있습니다.
데이터를 불러오는 건 pandas를 이용해야합니다.
import pandas as pd는 필수!
[임의 변수명] = pd.read_csv('경로')
불러온 데이터 확인하기
기본적으로 print 문안에 변수를 넣으면 출력이 됩니다.
하지만, 우리는 다양한 것들이 알고 싶죠?
시작 전 알아야할 문법의 주요 요소
[]와 ()는 Python에서 중요한 역할을 하는 기호입니다.
.(dot)의 역할
.(dot)는 객체(Object)의 속성(Attribute)이나 메서드(Method)에 접근(호출)하는 데 사용됩니다.
Python에서 .을 사용하여 객체의 속성이나 메서드에 접근할 수 있습니다. 객체는 일반적으로 클래스(Class)로부터 생성된 인스턴스(instance)입니다. 클래스는 속성과 메서드를 가지고 있으며, .을 사용하여 해당 속성이나 메서드에 접근할 수 있습니다.
[]의 역할
[]는 리스트(List), 문자열(String), 튜플(Tuple), 딕셔너리(Dictionary), 데이터프레임(DataFrame) 등의 자료구조에 접근하거나 슬라이싱(Slicing)을 수행하는 데 사용됩니다.
리스트, 문자열, 튜플: []를 사용하여 인덱스(index)를 지정하여 해당 위치의 원소에 접근할 수 있습니다.
예시: my_list[0], my_string[2], my_tuple[1]
리스트, 문자열: []를 사용하여 슬라이싱을 수행하여 원하는 범위의 원소를 추출할 수 있습니다.
예시: my_list[1:3], my_string[2:5]
딕셔너리: []를 사용하여 특정 키(key)에 해당하는 값을 가져올 수 있습니다.
예시: my_dict['key_name']
데이터프레임: []를 사용하여 특정 컬럼(column)을 선택하거나 조건에 맞는 행(row)을 필터링할 수 있습니다.
예시: my_df['column_name'], my_df[my_df['column_name'] > 10]
()의 역할
()는 함수 호출(Call)이나 튜플(Tuple), 수식 계산, 조건문 등에서 사용됩니다.
함수 호출: 함수 이름 다음에 ()를 사용하여 함수를 호출합니다.
예시: my_function()
튜플: 여러 개의 값을 묶어서 튜플로 생성할 때 ()를 사용합니다.
예시: my_tuple = (1, 2, 3)
수식 계산: 수식에서 우선순위를 명시하기 위해 ()를 사용합니다.
예시: (2 + 3) * 4
조건문: if문 등에서 조건을 표현하기 위해 ()를 사용합니다.
예시: if (x > 0):
그냥 print(data)를 하면?
print문 괄호()안에 넣어서 다양하게 확인할 수 있는 명령어들
print(data)를 사용하면 데이터프레임의 전체 내용을 출력할 수 있습니다. 이를 통해 데이터프레임의 모든 레코드와 컬럼을 확인할 수 있습니다.
print(data)
print.(dot)을 이용하여 여러 정보를 확인하자
데이터프레임의 상위 레코드 확인하기: head() 메서드
데이터프레임의 상위 레코드를 확인할 수 있습니다. 기본적으로 상위 5개의 레코드가 표시됩니다.
예시: data.head() (여기서 data는 데이터프레임 객체입니다.)
print(data.head())

데이터프레임의 구조 및 컬럼 정보 확인하기info()
info() 메서드를 사용하여 데이터프레임의 구조와 컬럼 정보, 데이터 타입 등을 확인할 수 있습니다.
예시: data.info()
print(data.info())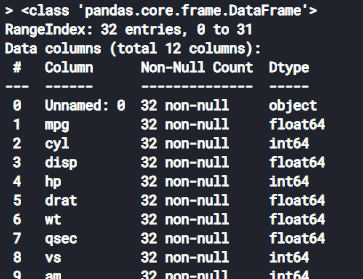
데이터프레임의 기술 통계 정보 확인하기
describe() 메서드를 사용하여 데이터프레임의 기술 통계 정보를 확인할 수 있습니다. 이는 숫자형 컬럼의 개수, 평균, 표준편차, 최소값, 25%, 50%, 75% 분위수, 최대값 등을 보여줍니다.
예시: data.describe()
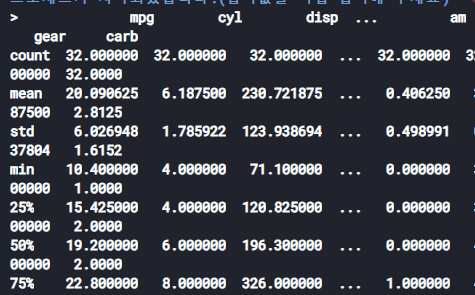
만약, Max값만 보고 싶거나 특정 속성이 보고 싶으면 descibe로만으로는 안됩니다.
별도의 변수를 지정하여 출력해야합니다.
# describe() 메서드로 통계적 요약 정보를 확인합니다.
summary = data.describe()
# 각 컬럼의 최대값(max)만 추출합니다.
max_values = summary.loc['max']
print(max_values)max_values = summary.loc['max'] 여기에서 loc은 pandas DataFrame에서 특정 행(row) 또는 열(column)을 선택하기 위한 라벨 기반 인덱싱(location-based indexing)을 수행하는 메서드입니다. loc을 사용하여 DataFrame의 특정 행 또는 열을 지정할 수 있습니다.
summary.loc['max']는 DataFrame summary에서 인덱스 라벨이 'max'인 행을 선택하는 것을 의미합니다. 즉, 'max'라는 인덱스 라벨을 가진 행을 추출하여 반환합니다.
summary라는 변수에는 descibe 처리된 값들이 있기 때문에 이 값들 중 max인 애들을 불러오는 것입니다.
특정 컬럼의 고유값 확인하기
unique() 메서드를 사용하여 특정 컬럼의 고유값을 확인할 수 있습니다. 고유값이란 데이터 집합에서 중복되지 않는 값들을 말합니다. 즉, 데이터 집합 내에서 유일한 값들을 의미합니다. 결측치를 찾는데 활용할 수도 있습니다.
예시: data['column_name'].unique() (여기서 'column_name'은 해당 컬럼의 이름입니다.)
print(data['mpg'].unique())
Unique로 결측치 찾는 방법
예를 들어, 다음과 같은 데이터프레임이 있다고 가정해보겠습니다
import pandas as pd
data = pd.DataFrame({'A': [1, 2, 3, np.nan, 5],
'B': [6, np.nan, 8, 9, 10]})위 데이터프레임에서 unique() 함수를 사용하여 결측치를 확인하면 다음과 같이 작성할 수 있습니다
missing_values = data['A'].isnull().sum()
print(missing_values)isnull() 함수를 사용하여 데이터프레임의 각 요소가 결측치인지 여부를 판별한 후, sum() 함수를 사용하여 결측치의 개수를 합산합니다.
isnull함수가 결측치( 결측치면 true, 아니면 false로 구분)를 찾고, sum이 true로 변환된 갯수를 세주는 것입니다.
특정 컬럼의 값 빈도수 확인하기 ( 매우 중요 제 2유형 다수 출제)
value_counts() 메서드를 사용하여 특정 컬럼의 값 빈도수를 확인할 수 있습니다.
예시: data['column_name'].value_counts() (여기서 'column_name'은 해당 컬럼의 이름입니다.)
주의 할점 2가지
1. counts 복수임을 잊으면 안됨
2. 단독으로 쓰기보단 다른 변수를 생성해서 print함
count = data['mpg'].value_counts().count()
# 여기에서 마지막 .count()는 총 갯수를 세어주기 위한 메서드
2023.06.18 - [빅데이터 분석기사] - [빅데이터 분석] 실제 시험환경과 같이 연습하기 구름 | 온코더 | 프로그래머스
'빅데이터 분석기사' 카테고리의 다른 글
| DataFrame을 다른 데이터 타입으로 바꾸는 방법 (CSV파일로 저장하는 방법 포함) (0) | 2023.06.20 |
|---|---|
| [빅데이터 분석기사] 제2유형 문제 풀기 - 체험하기 문제 (0) | 2023.06.19 |
| [빅데이터 분석] 실제 시험환경과 같이 연습하기 구름 | 온코더 | 프로그래머스 (0) | 2023.06.18 |
| [빅데이터 분석] 쥬피터 노트란? | 설치방법 | 활용방법 (2) | 2023.06.05 |
| [무턱대고 빅데이터분석기사] SciPy란? | 상관분석 | 회귀분석 (0) | 2023.06.04 |




댓글